

Structured content enables online publishers to assemble pieces of content in multiple ways. However, the process by which this assembly happens can be opaque to authors and designers. Read on to learn how orchestration is evolving and how it works.
To many people, orchestration sounds like jargon or a marketing buzzword. Yet orchestration is no gimmick. It is increasingly vital to developing, managing, and delivering online content. It transforms how publishers make decisions about content, bringing flexibility and learning to a process hampered in the past by short-term planning and jumbled, ad-hoc decisions.
Revealing the hidden hand of orchestration
Orchestration is both a technical term in content management and a metaphor. Before discussing the technical aspects of orchestration, let’s consider the metaphor. Orchestration in music is how you translate a tune into a score that involves multiple instruments that play together harmoniously. It’s done by someone referred to as an arranger, someone like Quincy Jones. As the New Yorker once wrote: “Everyone knows Quincy Jones’s name, even if no one is quite sure what he does. Jones got his start in the late nineteen-forties as a trumpeter, but he soon mastered the art of arranging jazz—turning tunes and melodies into written music for jazz ensembles.”
Much like music arranging, content orchestration happens off stage, away from the spotlight. It doesn’t get the attention given to UI design. Despite its stealthy profile, numerous employees in organizations become involved with orchestration, often through small-scale A/B testing by changing an image or a headline.
Orchestration typically focuses on minor tweaks to content, often cosmetic changes. But orchestration can also address how to assemble content on a bigger scale. The emergence of structured content makes intricate, highly customized orchestration possible.
Content assembly requires design and a strategy. Few people consider orchestration when planning how content is delivered to customers. They generally plan content assembly by focusing on building individual screens or a collection of web pages on a website. The UI design dictates the assembly logic and reflects choices made at a specific time. While the logic can change, it tends to happen only in conjunction with changes to the UI design.
Orchestration allows publishers to specify content assembly independently of its layout presentation. It does so by approaching the assembly process abstractly: evaluating content pieces’ roles and purposes that address specific user scenarios.
Assembly logic is becoming distributed. Content assembly logic doesn’t happen in one place anymore. Originally, web teams created content for assembly into web pages using templates defined by a CMS on the backend. In the early 2000s, frontend developers devised ways to change the content of web pages presented in the browser using an approach known initially as Ajax, a term coined by the information architect Jesse James Garrett. Today, content assembly can happen at any stage and in any place.
Assembly is becoming more sophisticated. At first, publishers focused on selecting the right web page to deliver. The pages were preassembled – often hand-assembled. Next, the focus shifted to showing or hiding parts of that web page by manipulating the DOM (document object model).
Nowadays, content is much more dynamic. Many web pages, especially in e-commerce, are generated programmatically and have no permanent existence. “Single page applications” (SPAs) have become popular, and the content will morph continuously.
The need for sophisticated approaches for assembling content has grown with the emergence of API-accessible structured content. When content is defined semantically, rather than as web pages, the content units are more granular. Instead of simply matching a couple of web page characteristics, such as a category tag and a date, publishers now have many more parameters to consider when deciding what to deliver to a user.
Orchestration logic is becoming decoupled from applications. While orchestration can occur within a CMS platform, it is increasingly happening outside the CMS to take advantage of a broader range of resources and capabilities. With APIs growing in coordinating web content, much content assembly now occurs in a middle layer between the back-end storing the content and the front-end presenting it. The logic driving assembly is becoming decoupled from both the back-end and front-end.
Publishers have a growing range of options outside their CMS for deciding what content to deliver. Tools include:
Digital experience, composition, and personalization orchestration engines (e.g., Conscia, Ninetailed)
Graph query tools (e.g., PoolParty)
API federation management tools (e.g., Apollo Federation)
These options vary in their aims and motivations, and they differ in their implementations and features. Their capabilities are sometimes complementary, which means they can be used in combination.
Orchestration inputs that frame the content’s context
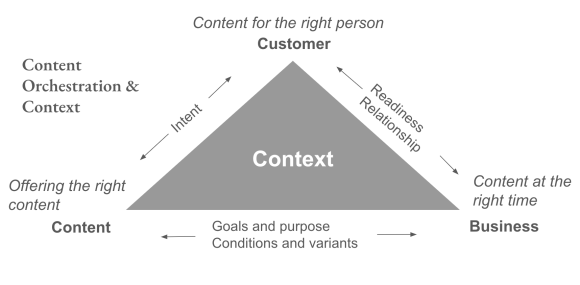
Content structuring supports extensive variation in the types of content to present and what that content says.
Orchestration involves more than retrieving a predefined web page. It requires considering many kinds of inputs to deliver the correct details.
Content orchestration will reflect three kinds of considerations:
The content’s intent – the purpose of each content piece
The organization’s operational readiness to satisfy a customer’s need
The customer or user’s intent – their immediate or longer-term goal
{kind=link}
Content characteristics play a significant role in assembly. Content characteristics define variations among and within content items. An orchestration layer will account for characteristics of available content pieces, such as:
Its editorial role and purpose, such as headings, explanations, or calls to action
Topics and themes, including specific products or services addressed
Intended audience or customer segment
Knowledge level such as beginner or expert
Intended journey or task stage
Language and locale
Date of creation or updating
Author or source
Size, length, or dimensions
Format and media
Campaign or announcement cycle
Product or business unit owner
Location information, such as cities or regions that are relevant or mentioned
Version
Each of these characteristics can be a variable and useful when deciding what content to assemble. They indicate the compatibility between pieces and their suitability for specific contexts.
Other information in the enterprise IT ecosystem can help decide what content to assemble that will be most relevant for a specific context of use. This information is external to the content but relevant to its assembly.
Business data is also an orchestration input. Content addresses something a business offers. The assembled content should link to business operations to reflect what’s available accurately.
The assembled content will be contextually relevant only if the business can deliver to the customer the product or services that the content addresses. Customers want to know which pharmacy branches are open now or which items are available for delivery overnight. The assembled content must reflect what the business can deliver when the customer seeks it.
The orchestration needs to combine content characteristics from the CMS with business data managed by other IT systems. Many factors can influence what content should be presented, such as:
Inventory management data
Bookings and orders data
Facilities’ capacity or availability
Location hours
Pricing information, promotions, and discount rules
Service level agreement (SLA) rules
Fulfillment status data
Event or appointment schedules
Campaigns and promotions schedule
Enterprise taxonomy structure defining products and operating units
Business data have complex rules managed by the IT system of record, not the CMS or the orchestration layer. For content orchestration, sometimes it is only necessary to provide a “flag,” checking whether a condition is satisfied to determine which content option to show.
Customer context is the third kind of orchestration input. Ideally, the publisher will tailor the content to the customer’s needs – the aim of personalization. The orchestration process must draw upon relevant known information about the customer: the customer’s context.
The customer context encompasses their identity and their circumstances. A customer’s circumstances can change, sometimes in a short time. And in some situations, the customer’s circumstances dictate the customer’s identity. People can have multiple identities, for example, as consumers, business customers at work, or parents overseeing decisions made by their children.
Numerous dimensions will influence a customer’s opinions and needs, which in turn will influence the most appropriate content to assemble. Some common customer dimensions include:
Their location
Their personal characteristics, which might include their age, gender, and household composition, especially when these factors directly influence the relevance of the content, for example, with some health topics
Things they own, such as property or possessions, especially for content relating to the maintenance, insurance, or buying and selling of owned things
Their profession or job role, especially for content focused on business and professional audiences
Their status as a new, loyal, or churned customer
Their purchase and support history
The chief challenge in establishing the customer context is having solid insights. Customers’ interactions on social media and with customer care provide some insights, but publishers can tap a more extensive information store. Various sources of customer data could be available:
Self-disclosed information and preferences to the business (zero-party data or 0PD)
The history of a customer’s interactions with the business (first-party data or 1PD)
Things customers have disclosed about themselves in other channels such as social media or survey firms (second-party data or 2PD)
Information about a cohort they are categorized as belonging to, using aggregated data originating from multiple sources (third-party data or 3PD)
Much of this information will be stored in a customer data platform (CDP), but other data will be sourced from various systems. The data is valid only to the extent it is up-to-date and accurate, which is only sometimes a safe assumption.
Content behavior can shape the timing and details assembled in orchestration. Users can signal their intent through their interaction with content. The user’s decisions while interacting with content can signal their intentions. Some behavior variables include:
Source of referral
Previously viewed content
Expressed interest in topics or themes based on prior content consumed
Frequency of repeat visits
Search terms used
Chatbot queries submitted
Subscriptions chosen or online events booked
Downloads or requests for follow-up information
The timing of their visit in relation to an offer
The most valuable and reliable signals will be specific to the context. Many factors can shape intent, so many potential factors will not be relevant to individual customers. Just because some factors could be relevant in certain cases does not imply they will be applicable in most cases.
Though challenging, leveraging customer intent offers many opportunities to improve the relevance of content. A rich range of possible dimensions is available. Selecting the right ones can make a difference.
Don’t rely on weak signals to overdetermine intent. When the details about individual content behavior or motivations are scant, publishers sometimes rely on collective behavioral data to predict individual customer intentions. While occasionally useful, predictive inputs about customers can be based on faulty assumptions that yield uneven results.
Note the difference between tailoring content to match an individual’s needs and the practice of targeting. Targeting differs from personalization because it aims to increase average uptake rather than satisfy individual goals. It can risk alienating customers who don’t want the proffered content.
Draw upon diverse sources of input. By utilizing a separate layer to manage orchestration, publishers, in effect, create a virtual data tier that can federate and assess many distinct and independent sources of information to support decisions relating to content delivery.
An orchestration layer gives publishers greater control over choosing the right pieces of content to offer in different situations. Publishers gain direct control over parameters to select, unlike many AI-powered “decision engines” that operate like a black box and assume control over the content chosen.
The orchestration score
If the inputs are the notes in orchestration, the score is how they are put together – the arrangement. A rich arrangement will sometimes be simple but often will be sophisticated.
Orchestration goes beyond web search and retrieval. In contrast to a ordinary web search, which retrieves a list of relevant web pages, orchestration queries must address many more dimensions.
In a web search, there’s a close relationship between what is requested and what is retrieved. Typically, only a few terms need matching. Web search queries are often loose, and the results can be hit or miss. The user is both specifying and deciding what they want from the results retrieved.
In orchestration, what is requested is needs to anticipate what will be relevant and exclude what won’t be. The request may refer to metadata values or data parameters that aren’t presented in the content that’s retrieved. The results must be more precise. The user will have limited direct input into the request for assembled content and limited ability to change what is provided to them.
Unlike a one-shot web search process, in orchestration, content assembly involves a multistage process.
The orchestration of structured content is not just choosing a specific web page based on a particular content type. It differs in two ways:
You may be combining details from two (or more) content types.
Instead of delivering a complete web page associated with each content type (and potentially needing to hide parts you don’t want to show), you select specific details from content items to deliver as an iterative procedure.
Unpacking the orchestration process. Content orchestration consists of three stages:
FIND stage: Choose which content items have relevant material to support a user scenario
MATCH stage: Combine content types that, if presented together, provide a meaningful, relevant experience
SELECT and RETURN stage: Choose which elements within the content items will be most relevant to deliver to a user at a given point in time
{kind=link}
Find relevant content items. Generally, this involves searching metadata tags such as taxonomy terms or specific values such as dates. Sometimes, specific words in text values are sought. If we have content about events, and all the event descriptions have a field with the date, it is a simple query to retrieve descriptions for events during a specified time period.
Typically, a primary content type will provide most of the essential information or messages. However, we’ll often also want to draw on information and messages from other content types to compose a content experience. We must associate different types of items to be able to combine their details.
Match companion content types. What other topics or themes will provide more context to a message? The role of matching is to associate related topics or tasks so that complementary information and messages can be included together.
Graph queries are a powerful approach to matching because they allow one to query “edges” (relationships) between “nodes” (content types.) For example, if we know a customer is located in a specific city, we might want to generate a list of sponsors of events happening in that city. The event description will have a field indicating the city. It will also reference another content type that provides a profile of event sponsors. It might look like this in a graph query language like GQL, with the content types in round brackets and the relationships in square brackets.
MATCH (:Event WHERE location=”My City”) – [:SponsoredBy] -> (:SponsorProfile)
We have filtered events in the customer’s city (fictiously named My City) and associated content items about sponsors who have sponsored those events. Note that this query hasn’t indicated what details to present to users. It only identifies which content types would be relevant so that various types of details can be combined.
Unlike in a common database query, what we are looking for and want to show are not the same.
Select which details to assemble. We need to decide what information within a relevant content type which details will be of greatest interest to a user. Customers want enough details for the pieces to provide meaningful context. Yet they probably won’t want to see everything available, especially all at once – that’s the old approach of delivering preassembled web pages and expecting users to hunt for relevant information themselves.
Different users will want different details, necessitating decisions about which details to show. This stage is sometimes referred to as experience composition because the focus is on which content elements to deliver. We don’t have to worry about how these elements will appear on a screen, but we will be thinking about what specific details should be offered.
GraphQL, a query language used in APIs, is very direct in allowing you to specify what details to show. The GraphQL query mirrors the structure of the content so that one can decide which fields to show after seeing which fields are available. We don’t want to show everything about a sponsor, just their name, logo, and how long they’ve been sponsoring the event. A hypothetical query named “local sponsor highlights” would extract only those details about the sponsor we want to provide in a specific content experience.
Query LocalSponsorHighlights {
… on SponsorProfile {
name
logo
sponsorSince
} }
The process of pulling out specific details will be repeated iteratively as customers interact with the content.
Turning visions into versions
Now that we have covered the structure and process of orchestration let’s look at its planning and design. Publishers enjoy a broad scope for orchestrating content. They need a vision for what they aim to accomplish. They’ll want to move beyond the ad hoc orchestration of page-level optimization and develop a scenario-driven approach to orchestration that’s repeatable and scaleable.
Consider what the content needs to accomplish. Content can have a range of goals. They can explicitly encourage a reader to do something immediately or in the future. Or they encourage a reader’s behavior by showing goodwill and being helpful enough that the customer wants to do something without being told what to do.
Content goalImmediate (Action outcome)Consequent (Stage outcome)Explicit (stated in the content)CTA (call to action) conversionContact sales or visit a retail outletImplicit (encouraged by the content)Resolve an issue without contacting customer supportRenew their subscription
Content goals must be congruent with the customer’s context. If customers have an immediate goal, then the content should be action-oriented. If their goal is longer-term, the content should focus on helping the customer move from one stage to another.
Orchestration will generate a version of the content representing the vision of what the pieces working together aim to accomplish.
Specify the context. Break down the scenario and identify which contextual dimensions are most critical to providing the right content. The content should adapt to the user context, reflect the business context, and provide users with viable options. The context includes:
Who is seeking content (the segment, especially when the content is tailored for new or existing customers, or businesses or consumers, for example)
What they are seeking (topics, questions, requests, formats, and media)
When they are seeking it (time of day, day of the week, month, season, or holiday, all can be relevant)
Where they are seeking it (region, country, city, or facility such as an airport if relevant)
Why (their goal or intent as far as can be determined)
How (where they started their journey, channels used, how long have they pursuing task)
Perfecting the performance: testing and learning
Leonard Bernstein conducts the New York Philharmonic in a Young People’s Concert. Image: Library of Congress
{kind=link}
An orchestral performance is perfected through rehearsal. The performance realized is a byproduct of practice and improvisation.
Pick the correct parameters. With hundreds of parameters that could influence the optimal content orchestration, it is essential that teams not lock themselves into a few narrow ones. The learning will arise from determining which factors deliver the right experience and results in which circumstances.
Content parameters can be of two kinds:
Necessary characteristics tell us what values are required
Contingency characteristics indicate values to try to find which ones work best
Specifies in the orchestrationDetermines in the contentOutcome expectedNecessary characteristics
(tightly defined scenarios)What values are required in a given situationWhich categorical version or option the customer getsThe right details to show to a given customer in a given situationContingency characteristics
(loosely defined scenarios)What values are allowed in a given situationWhich versions could be presentedCandidate options to present to learn which most effectively matches the customer’s needs
The two approaches are not mutually exclusive. More complex orchestration (sometimes referred to as “multihop” queries) will involve a combination of both approaches.
Necessary characteristics reflect known and fixed attributes in the customer or business context that will affect the correct content to show. For example, if the customer has a particular characteristic, then a specific content value must be shown. The goal should be to test that the orchestration is working correctly – that the assumptions about the context are correct. For example, there are no wrong assumptions or missing ones. This dimension is especially important for aspects that are fixed and non-negotiable. The content needs to adapt to these circumstances, not ignore them.
Contingency characteristics reflect uncertain or changeable attributes relating to the customer’s context. For example, if the customer has had any one of several characteristics now or in the past, try showing any one of several available content values to see which works best given what’s known. The orchestration will prioritize variations randomly or in some ranked order based on what’s available to address the situation.
You can apply the approach to other situations involving uncertainty. When there are information gaps or delays, contingency characteristics can apply to business operations variables and to the content itself. The goal of using contingency characteristics is to try different content versions to learn what’s most effective in various scenarios.
Be clear on what content can influence. We have mostly looked at the customer’s context as an input into orchestration. Customers will vary widely in their goals, interests, abilities, and behaviors. A large part of orchestration concerns adapting content to the customer’s context. But how does orchestration impact the customer? In what ways might the customer’s context be the outcome of the content?
Consider how orchestration supports a shift in the customer’s context. Orchestration can’t change the fixed characteristics of the customer. It can sway ephemeral characteristics, especially content choices, such as whether the customer has requested further information. And the content may guide customers toward a different context.
Context shifting involves using content to meet customers where they are so they can get where they want to be. Much content exists to change the customer’s context by enabling them to resolve a problem or encouraging them to take action on something that will improve their situation.
The orchestration of content needs to connect to immediate and downstream outcomes. Testing orchestration entails looking at its effects on online content behavior and how it influences interactions with the business in other areas. Some of these interactions will happen offline.
The task of business analytics is to connect orchestration outputs with customer outcomes. The migration of orchestration to an API layer should open more possibilities for insights and learning.
– Michael Andrews
The post Orchestrating the assembly of content appeared first on Story Needle.